Cloud Technologies
Amazon Polly: Text Narrator
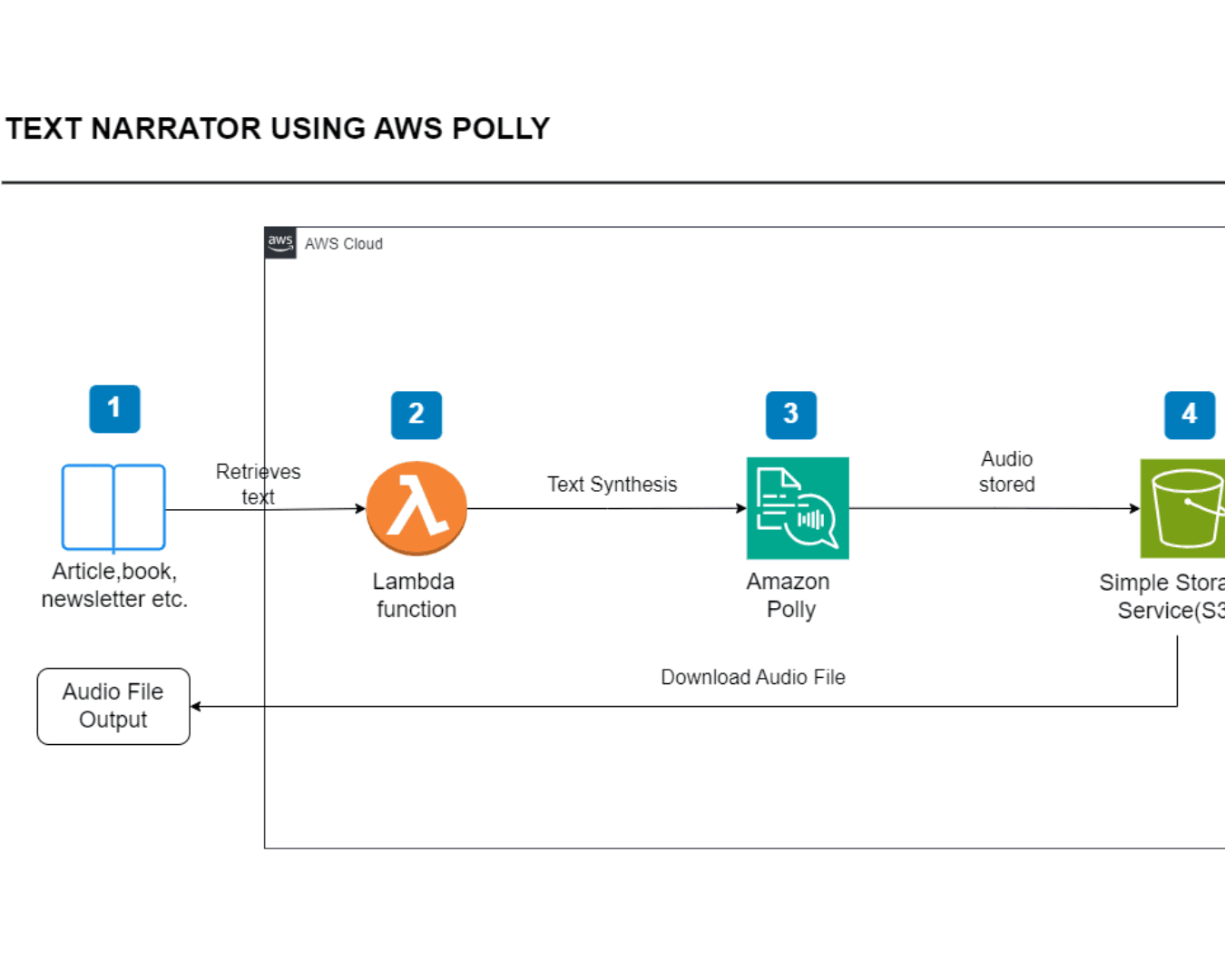
This project leverages Amazon Polly, an AI-powered text-to-speech (TTS) service, to convert text from articles, books, and newsletters into high-quality audio files. The process involves a serverless architecture where an AWS Lambda function retrieves the text input, processes it with Amazon Polly for speech synthesis, and stores the resulting audio file in an Amazon S3 bucket. This solution enhances accessibility and provides an efficient way to convert text-based content into spoken-word formats.
My Role
Cloud Solutions Architect
Duration
1 year
Tools
Amazon Polly, AWS Lambda, Amazon S3, Python, Boto3
Link
Overview
Handling Large Text Inputs – Ensuring that long articles or book chapters are processed efficiently without exceeding AWS Polly limits.
Speech Quality & Customization – Fine-tuning voice selection, speed, and pronunciation for a more natural listening experience.
Efficient Storage & Retrieval – Managing audio files effectively in S3 for quick access and minimal storage costs.
Scalability & Cost Optimization – Keeping the solution cost-efficient while handling multiple user requests.
Chunked Text Processing – Implemented logic to split long text inputs into manageable segments before sending them to Amazon Polly.
SSML Enhancements – Used Speech Synthesis Markup Language (SSML) to customize speech tone, pauses, and pronunciation for improved output.
Optimized S3 Storage Strategy – Configured lifecycle policies for S3 buckets to archive or delete unused audio files, reducing storage costs.
Serverless Cost Efficiency – Leveraged AWS Lambda’s pay-as-you-go model to ensure scalability without unnecessary expenses.